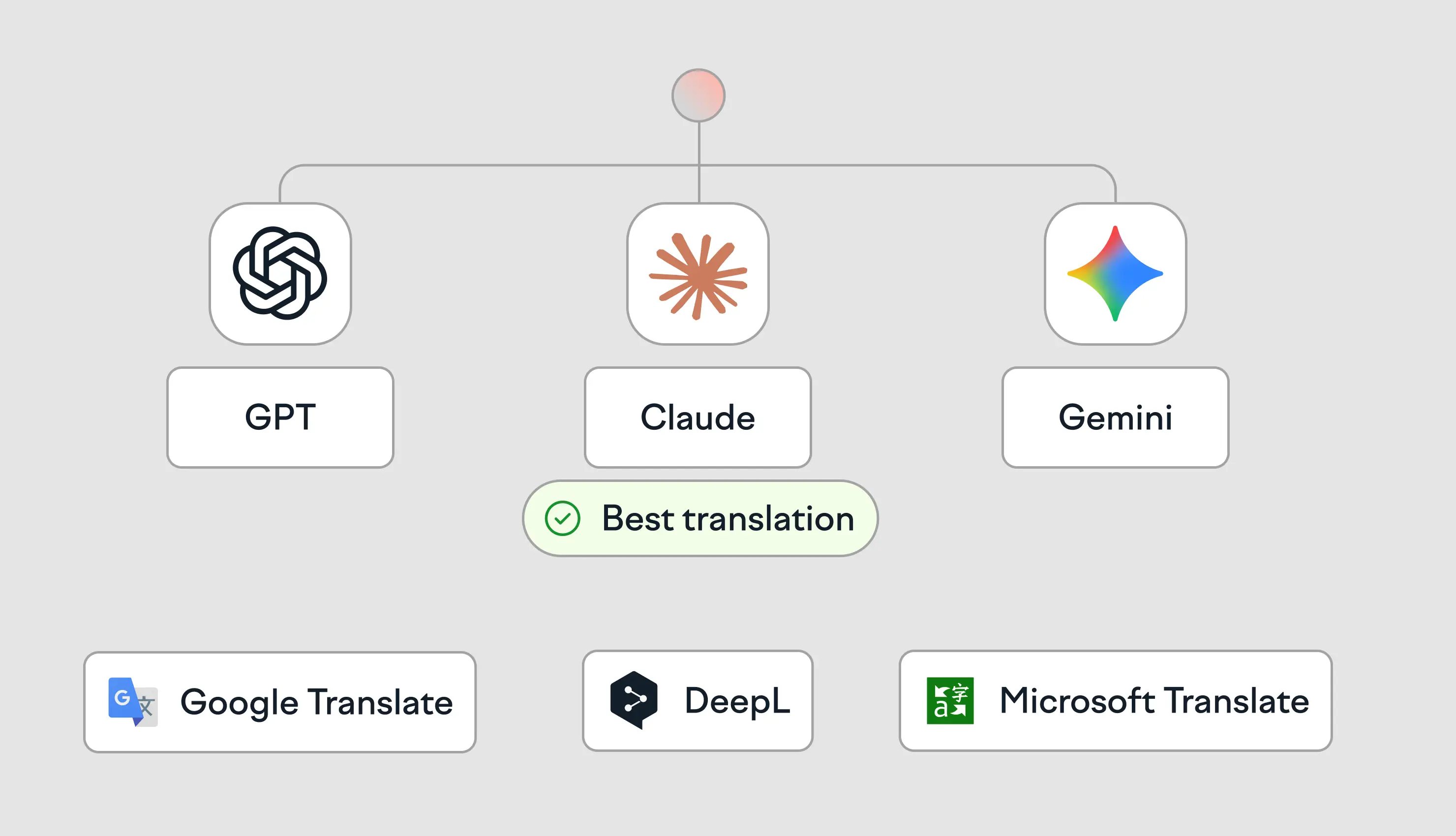
The best LLM for translation depends on the task. Claude is typically strongest for high-nuance, brand-sensitive marketing translation. GPT-4o/5 tends to perform best for technical documentation and code localization. Gemini is a strong choice when long context and multi-file consistency matter. DeepSeek is often the most cost-efficient option for high-volume, lower-risk bulk translation.
But in 2026, the question isn’t which model wins overall, but which model is best for the specific translation task inside your automated pipeline. The goal is to choose the right model for each job and validate quality at scale.
Lokalise designed a control experiment to test what’s the best LLM translation for different tasks. Keep reading to learn what we discovered.
🔖 Bookmark this article
Our product team is continuously performing research and sharing insights on Large Language Models (LLM) for translation, so we’ll update this article regularly.
LATEST UPDATE (March, 2026): Updated with findings from Lokalise’s comprehensive blind-comparison study and the latest WMT25 research demonstrating LLM superiority over traditional machine translation.
Are LLMs better than traditional machine translation tools?
LLMs are the stronger default for many production translation tasks, while traditional MT is increasingly best treated as a baseline or fallback. To test this rigorously, Lokalise’s product team ran a blind comparison study across three language pairs (from English to German, Polish, and Russian) and five systems.
Two LLMs (Claude Sonnet 3.5 and GPT-4o) and three traditional machine translation tools (DeepL, Google Translate, and Microsoft Translator) were tested.
Because translation quality is inherently subjective, we used native-speaker pairwise comparisons and statistical ranking to reduce preference noise and produce results we can be confident about.
The thing is, a major blocker in AI localization is trust. Teams hesitate to automate review because they assume quality assessment is too subjective. But our findings suggest that the gap is smaller than people think.
Key findings:
LLMs demonstrated superior performance across all tested language pairs, with translation quality marked as ‘good’ between 55.7% and 80% of the time, even without any contextual information
Claude 3.5 remains the benchmark for stylistic fluency, while Gemini 2.0 Pro dominates long-context repository translation
LLMs reduced review load potential, because “good” output was frequent enough to use LLMs as a first pass and reserve human review for exceptions rather than defaults
Across our evaluation, human-to-human agreement and AI-to-human agreement were close, whether measured with inter-rater reliability (Cohen’s Kappa) or overlap metrics (Average Jaccard Similarity).
In some cases, evaluators aligned more consistently with the AI ranking model than with other human annotators.
What did the WMT25 study find?
WMT25 shows that top-performing translation systems increasingly rely on LLM-based or hybrid approaches. The performance differences become clearer when evaluation uses harder, more realistic test sets instead of “easy” examples.
In the WMT25 General Machine Translation Shared Task, teams could submit systems for 30 language pairs, and the benchmark includes human judgment as a key part of evaluation.
The practical takeaway is that “best model” decisions should be task-based and context-aware. Traditional neural machine translation (NMT) is increasingly being integrated with (or replaced) by LLM-based approaches, typically via fine-tuning or as part of data cleaning and post-editing pipelines.
Get the best LLM-powered translations
Plug LLM-powered translation into your workflow in a matter of minutes with Lokalise.
To ensure scientific rigor, we used multiple evaluation methodologies, including the Bradley-Terry model, one of the most respected statistical methods for ranking items based on pairwise comparisons. It’s a probabilistic framework that models the probability that translation A will be preferred over translation B using strength parameters.
This approach allowed us to establish a clear hierarchy of translation quality based on maximum likelihood estimation.
We focused on high-resource languages to test, not only the hypothesis that LLMs have surpassed ‘more traditional’ MT systems for translation but also that LLM translation is already ‘good enough’ for high-resource languages.
We used Large Language Models to translate from English into three languages:
English to German
English to Polish
English to Russian
Then we asked human annotators to evaluate translation quality through pairwise comparisons of translations from different engines:
For every translation, native speakers compared the variants from different engines and highlighted the best one
600+ pairwise comparisons were carried out by multiple human annotators for each language pair
Interestingly, while Russian is technically a high-resource language, our ‘goodness’ scores were significantly lower than for German and Polish, suggesting that resource availability doesn’t always correlate directly with translation performance.
📚 Further reading
Curious to learn more? Discover what’s the difference between NLP vs. LLM.
Why LLM-first translation works better in production workflows
LLMs tend to outperform traditional MT because they handle meaning and intent more flexibly, especially when the workflow supplies the right context. This is exactly why translation performance depends on task configuration, not model brand.
LLMs like Claude Sonnet 3.5 and GPT-4o bring several advantages to translation tasks that traditional machine translation tools don’t:
Contextual understanding: Unlike traditional translation systems, LLMs grasp the broader context of text, enabling more natural-sounding outputs
Cultural nuance: These models can better preserve idioms, cultural references, and tone across languages
Adaptability: LLMs demonstrate greater flexibility when handling specialized terminology or uncommon language patterns
Consistency: Our testing showed remarkable consistency in quality, with the best LLM achieving good translations 78% of the time across multiple language pairs
As large language models (LLMs) evolve and new models are released, the gap between LLM and traditional machine translation quality is only going to get bigger.
Choose the right LLM for translation by matching the model’s strengths to your specific task. Use Claude for high-nuance marketing content, GPT-4o/5 for technical documentation and code localization, Gemini for long-context, multi-file consistency, and cost-efficient models like DeepSeek for high-volume bulk translation within an automated workflow.
The right model depends on what you’re translating, how much context you can provide, and how strictly you need to protect formatting, terminology, and brand voice.
In 2026, the best LLM for translation is a routing decision inside your automated pipeline.
The four use cases below reflect the most common translation tasks inside automated workflows.
Why use Claude for creative translations
Claude 3.5/4 excels at high-nuance marketing translation where tone, idioms, and brand voice determine whether content feels truly native.
Claude is typically the best choice when the translation task demands stylistic fluency, not just literal accuracy. It performs well on marketing pages and UX copy where tone, idioms, and cultural nuance determine whether the output feels native and on-brand.
Claude is great for translating customer-facing, brand-sensitive content, especially when you ground it with reference material (approved phrasing, terminology, examples) so it doesn’t “invent” a new voice from scratch.
Why use ChatGPT for technical and code translations
GPT-4o/5 leads in technical documentation and code localization by reliably preserving variables, placeholders, and structured formatting.
ChatGPT is often the safest choice when translation accuracy depends on constraint-following. It tends to handle placeholders, variables, and formatting rules more reliably, which matters for UI strings and technical documentation, and for code-adjacent strings that must preserve syntax.
ChatGPT works well for translating structured content where slightly less elegant phrasing is acceptable.
Why use Gemini for long-context and multi-file translations
Gemini long-context models are a strong fit when your translation task is not a single string, but an entire collection of related files that must stay consistent.
With a context window that can scale up to 2 million tokens, Gemini is useful for translating long documentation sets, repositories, or multi-file exports where names, terminology, and phrasing must remain stable across sections.
Why use DeepSeek for cost-efficient bulk translations
DeepSeek’s pricing model is explicitly positioned around cost-efficiency at scale, which makes it attractive for large batches and always-on internal workflows.
DeepSeek is often the best option when the task is high-volume, lower-risk translation and the priority is cost and throughput. This can include internal updates, drafts, and bulk content that still needs to be understandable, but doesn’t need a premium marketing voice.
With LLMs constantly evolving and releasing new versions, it’s hard to stay on top of which translation model to choose depending on your needs. That’s where Lokalise comes in.
🧠 Good to know
At Lokalise, we’re LLM agnostic, ensuring our customers always get the best performing LLM per language pair, without being locked into one model as AI technology continues to improve.
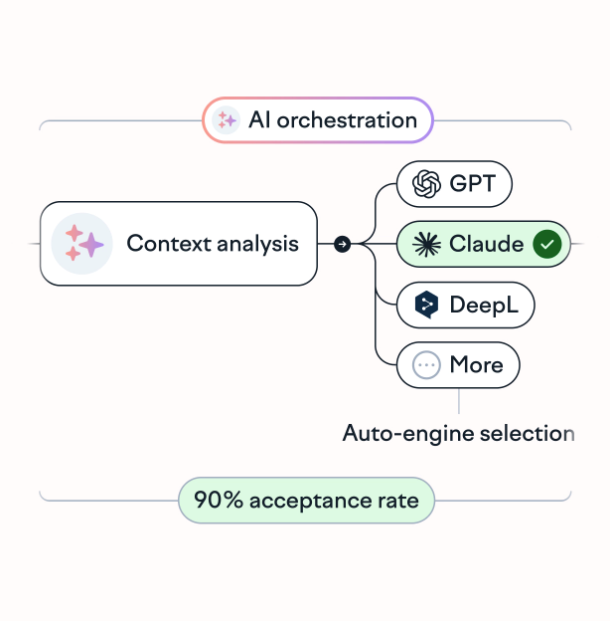
How Lokalise automates LLM selection in production workflows
Lokalise AI Orchestrator dynamically selects the optimal LLM based on language pair, content type, and workflow constraints. More precisely:
Dynamic model routing chooses the right LLM for each translation task
Custom AI Profiles enforce your terminology and brand voice
Retrieval (RAG) supplies the model with relevant approved translations from your translation memory
AIQE scoring flags which strings are publish-ready versus which ones should go to human review
Let’s take a closer look at each.
Dynamic model routing (task-aware selection)
Different translation tasks require different strengths. Marketing copy demands tone control. UI strings demand placeholder safety. Documentation demands structural consistency.
Lokalise AI Orchestrator matches each translation job to the model best suited for that task instead of forcing a single engine across all content.
This means creative content can be routed to Claude, structured technical strings to GPT models, long-context assets to Gemini, and high-volume internal batches to cost-efficient engines. The selection happens automatically inside the pipeline, not manually per project.
Custom AI Profiles ground model behavior in your domain
Custom AI Profiles in Lokalise improve translation quality by attaching domain-specific instructions, terminology rules, and stylistic guidance to each job.
Instead of relying on generic system behavior, you can define how the model should behave for marketing, legal, support, or technical content. This reduces tone drift and prevents terminology inconsistencies across releases.
Retrieval (RAG) connects models to your approved translations
Retrieval-augmented workflows improve translation accuracy by grounding LLM output in approved examples from translation memory and prior releases.
This matters because context is the difference between “good” and “production-ready.”
Rather than guessing preferred phrasing, the system retrieves relevant past translations and uses them as reference points. This increases consistency across strings, reduces hallucinated terminology, and makes translation output more predictable at scale.
AIQE scoring enables automated quality routing
Automation only works if quality can be measured. AIQE scoring estimates translation quality at the string level and enables automated routing decisions.
When a translation meets a defined quality threshold, it can be auto-approved. When it falls below that threshold, it can be flagged for review. This allows teams to reserve human expertise for high-risk or ambiguous content instead of reviewing every string by default.
Why orchestration matters more than model brand
In 2026, there’s no single “best” LLM for translation. There’s a best model for the job in front of you.
Claude is usually the safest bet when tone and nuance matter, GPT-4o/5 is a strong choice when you need strict accuracy with variables and structured formats, Gemini is helpful when you’re translating long documents or keeping many files consistent, and DeepSeek can make sense when you need high-volume output at a lower cost.
Model selection shouldn’t live in someone’s head or in a one-time decision. The most reliable workflows route each task to the right model, ground the model with your approved terminology and past translations, and use quality signals to decide what’s publish-ready versus what needs review.
That approach stays stable even as models change. It’s the easiest way to keep translation quality high without slowing your pipeline down.
Want to learn more? Watch this webinar and see how you too can achieve 90% publish-ready translations with AI.
🧠 How AIQE scoring works in Lokalise
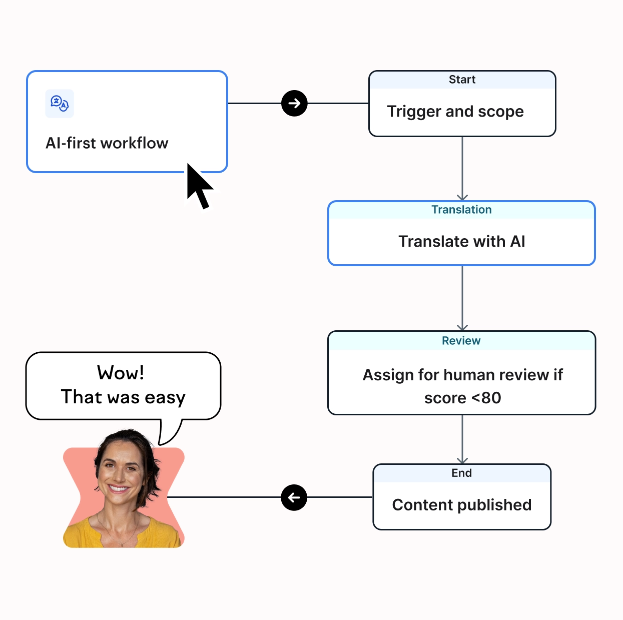
In Lokalise, each translated string receives an AIQE score from 0 to 100, based on the MQM (Multidimensional Quality Metrics) standard, so teams can assess quality without manually reviewing everything.
The score is designed to support routing. A high AIQE score (typically ≥80) indicates the translation is usually safe to auto-approve or only needs a quick skim, while a lower score (<80) signals that human review is strongly recommended.
In practice, this is what makes AI translations trustworthy.
Meet Rachel, our Content Manager and Lead Copywriter, who pivoted from advertising to SaaS and has never looked back.
Born and raised in the UK, Rachel has lived in London, Paris, Buenos Aires, and now Brussels. Through city-hopping, traveling, and her studies in French and Journalism, she’s picked up French and Spanish, and is now inventing her own language with help from her three-year-old daughter: Franglospanish!
Outside work, Rachel enjoys making (and eating) fresh pasta, drawing, and spending as much time as possible outside, cycling, hiking, or running.
Meet Rachel, our Content Manager and Lead Copywriter, who pivoted from advertising to SaaS and has never looked back.
Born and raised in the UK, Rachel has lived in London, Paris, Buenos Aires, and now Brussels. Through city-hopping, traveling, and her studies in French and Journalism, she’s picked up French and Spanish, and is now inventing her own language with help from her three-year-old daughter: Franglospanish!
Outside work, Rachel enjoys making (and eating) fresh pasta, drawing, and spending as much time as possible outside, cycling, hiking, or running.
AI translation quality achieves human parity: Is this the end of language barriers?
To paraphrase Captain Kirk, AI has boldly gone where no machine has gone before: it has finally reached human-level translation quality. But this doesn’t mean we’re done with AI translation. Far from it. We’re only just getting started, and the possibilities are both endless and exciting. After decades of clunky, error-prone, and literal-sounding machine translation, we’ve reached a pivotal moment where automated translation matches human quality. When fed t
Season 1, Episode 1: A product leader’s guide to going beyond the AI hype to find what actually works
In this episode of AI Navigators, we sit down with Adam Soltys, Senior Product Lead for the AI Translations Domain at Lokalise, to explore what’s actually driving AI success in enterprise applications today. With every company claiming to be ‘AI-powered’, how do you cut through the noise? Adam reveals what’s actually working: while everyone’s talking about AI agents, the real impact is coming from an ‘old school’ technology that’s quietly delivering extraordinary result
Transcreation vs localization: Which approach is right for you
When Coca-Cola launched its famous “Share a Coke” campaign in China, it tanked. Since most Chinese consumers don’t go by just one name, the idea of printing common first names on bottles didn’t work well. So, the brand adapted this campaign to print social labels like “Comedian” and “Fashionista.”