Why ChatGPT alone isn't enough to scale translations
ChatGPT is great at writing natural, fluent content. That’s useful when you need the copy to sound human. But when it comes to large-scale translation, especially for technical or structured content, things get more complicated.
Large Language Models (LLMs) like ChatGPT don’t work the same way as traditional machine translation (MT) engines. They’re trained to generate likely word sequences, not to follow strict segmentation rules or stick to approved terminology.
While they can handle context, sometimes impressively so, they require setup. This includes the right prompts, documents, examples, and post-editing. That effort doesn’t scale well when you’re dealing with thousands of strings, multiple languages, and product content that needs to keep up with the releases.
“Consistency comes at a great cost,” says Sasho, Engineering Manager for AI/ML at Lokalise:
“If you’re running AI translation manually and improve your prompt or TM halfway through, you introduce inconsistencies that are expensive and time-consuming to fix. And the more volume you have, the harder it is to go back and correct.”
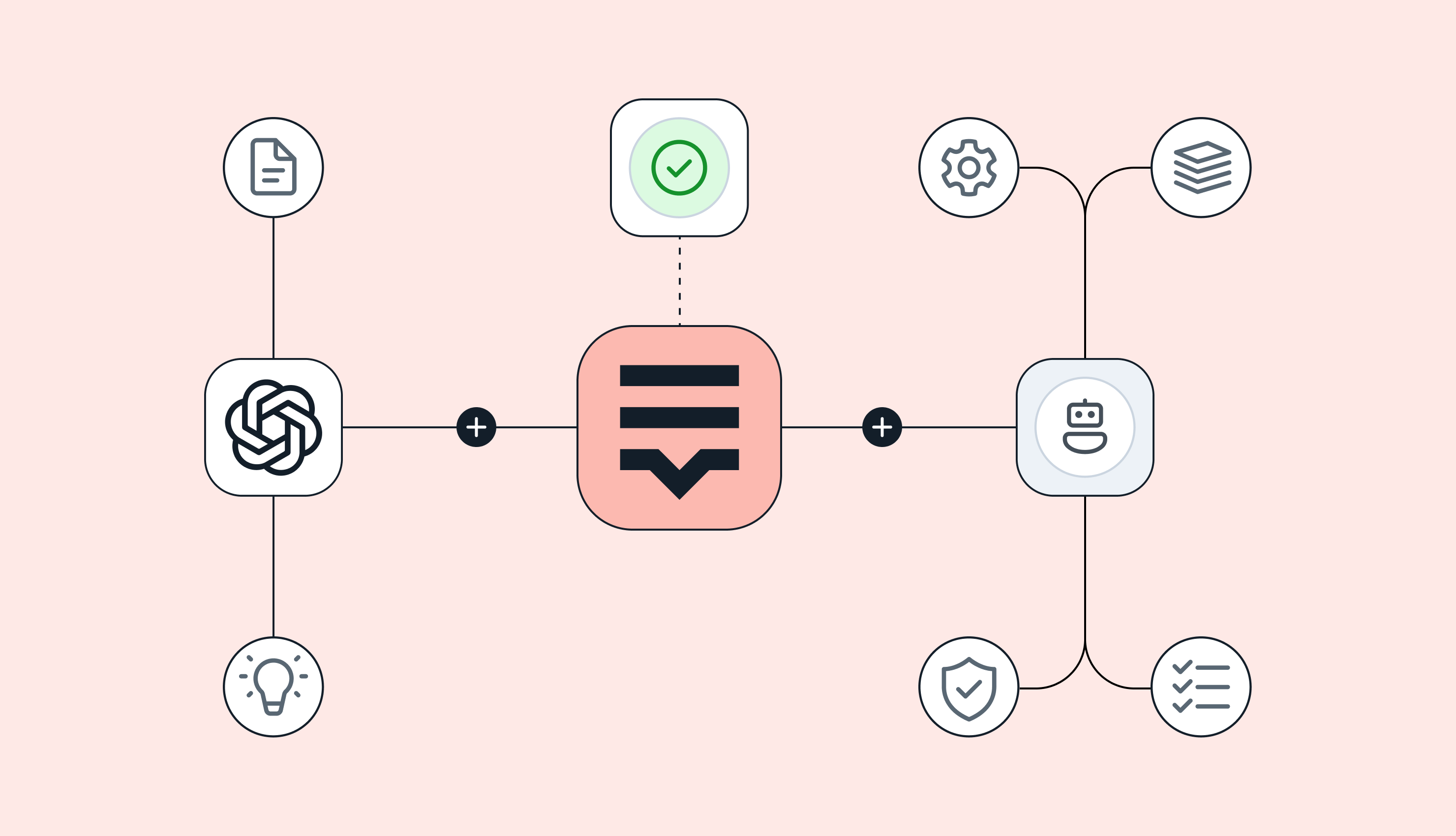
In contrast, Lokalise’s AI orchestration system evaluates multiple engines and picks the best one for a given translation task, depending on the language pair and the content you’re translating. This includes support for LLM‑based models like GPT‑4o and Claude Sonnet 3.5, as well as traditional engines like DeepL, Google Translate, and Microsoft Translate.
The system also enriches translations with your project’s context. It relies on your glossaries, translation memory, and style guides to improve quality and consistency.
“Unlike a manual chat interface, Lokalise uses LLM APIs to reduce non-determinism,” Sasho explains. “That means we can better control temperature, consistency, and behavior. These are the things you just can’t do reliably in ChatGPT’s UI.”
When using MT engines makes sense
MT engines like DeepL or Google Translate are rule-following by design. They handle segmentation, use translation memory, and apply metadata to deliver consistent results, especially for high-volume, low-variance content like UI labels or legal notices.
These systems are more rigid, but that’s often what’s needed when consistency and control matter most. As you can see, each approach has strengths:
- LLMs shine when tone and nuance matter
- MT engines deliver when structure and speed take priority
The challenge is knowing when to use which, and having the tools to switch seamlessly.
Can you still trust ChatGPT for translations?
As we explained, ChatGPT doesn’t “translate” in the way a machine translation engine does. It predicts.
Specifically, it uses probability to guess what the next word should be based on the input it receives and its massive training data. This is why we cannot stress one thing enough: the quality of output is heavily dependent on the quality of input.
Without proper context, ChatGPT can run into issues like:
- Inaccuracy, especially when terms are ambiguous or missing from prompts
- Skipping tags or placeholders, if they’re unfamiliar or underrepresented in training data
- Inconsistency, where the same term is translated in different ways across similar strings
- Ignoring preferred terms, unless you explicitly provide and reinforce themThat’s just how LLMs function
Bear in mind that these aren’t signs that ChatGPT is unreliable by default. It just needs structure. Unlike MT engines, LLMs don’t come with built-in memory, terminology, or segmentation logic. That’s what makes them incredibly flexible for all types of translations.
“LLMs offer a different type of context control compared to MT engines,” says Sasho. “MTs are optimized for specific inputs like glossary terms or formality, while LLMs can shape knowledge more freely, like pulling from relevant previous examples via RAG. This opens up a much broader range of possibilities.”