You know that déjà-vu feeling when a phrase you swear you translated last month shows up in a new project? Translation memory (TM) is the tool that makes you resurface the right translation in seconds.
It’s a smart database that saves each source segment and its approved translation, then offers it back whenever the same (or even a similar) string pops up. Picture Google Docs’ autocomplete, but for every language you localize.
In this guide you’ll learn how translation memory works, what are the big wins it brings, and where it truly shines. You’ll also discover some of its limits and easy fixes so that you keep it clean and actually helpful.
🌎 Lokalise is your trusted expert on anything related to translation
At Lokalise, we’re committed to help you make the most out of your translation and localization project. If you want to learn more, make sure to explore our blog and resource library.
What is translation memory and how it works
Translation memory (TM) is a running archive of everything you have already translated. Each record stores a source sentence and its approved translation side by side.
You can learn more about translation memory in the video below.
A translation memory works like a real-time loop. Your CAT tool first breaks new content into bite-sized segments and fires each one at the TM. It instantly tags it as an exact match (100%), a fuzzy match (70-99%), or blank (if nothing fits).
In the editor, the translator sees the top suggestion beneath the source line. It takes just one click to accept an exact hit, or a quick tweak for a fuzzy one. Then all they need to do is press “Save” to pair the finalized target text with the source.
Key benefits of translation memory
Once you know a translation memory holds every sentence you’ve already translated (or paid to translate), the obvious next question is: What’s the upside? The short answer is speed, savings, and translation consistency (plus a few perks you may not expect).
Cut translation costs
If you think about it, translation memory makes every approved segment a one-time purchase. When the same sentence (or even one that’s 90 % similar) pops up later, the tool inserts the stored version instead of billing for a fresh translation.
Over a large software or documentation set, those “free” matches stack up quickly. This means you’re able to turn thousands of repeated words into a single line-item you can redirect to new content or additional languages.
Faster turnaround time
Real-time suggestions let linguists review, tweak, and move on instead of typing from scratch. That shortens the “keyboard time” per segment and keeps momentum high. Teams often see multi-day projects finish in a single sprint, which is critical when product releases, marketing launches, or hotfixes can’t wait.
🧠 Did you know?
When uploading translation files into Lokalise, you can enable the “Pre-translate with 100% TM matches” option. With this option turned on, Lokalise will fetch each base language value from the uploaded file, and search for a matching entry in the translation memory.
If a 100% match is found, the corresponding translation will be automatically populated for the given key, as long as that key doesn’t already have a translation.
Better translation consistency
Because every translator pulls phrasing from a single source of truth, key terms such as UI labels, brand taglines, legal boilerplate, stay identical across platforms. Users encounter the same voice whether they’re in the mobile app, help center, or onboarding email, which provides a unified experience.
Ongoing updates get simpler
Let’s say your source language is English. When English copy changes, the TM flags only the segments affected in each target language. Translators can easily adjust those lines without re-touching the rest of the file.
Let’s see an example of a workflow in Lokalise.
Select your keys: In the Lokalise editor, tick one or more strings that carry similar wording
Open bulk actions: Click the “Bulk actions” dropdown, then choose “Apply TM to…”
Set your rules: Pick the target language you want to fill. Enter a minimum match (for example, 98%).
Click “Apply”: Lokalise now searches your TM from best to worst; it tries a perfect 100% match first, then 99%, and only falls back to 98% if nothing higher exists.
Each string receives the best match above your threshold, no manual copy-paste required.
So, what does this mean for you? It means that small product tweaks no longer turn into full re-translation cycles, maintenance stays light, and budgets stay intact. That’s what happens when you embrace continuous localization.
Translation memory grows as your team does
A centralized TM lets multiple linguists work in parallel without stepping on each other’s toes. New translators see context and preferred terminology the moment they join, and this reduces onboarding time and Slack back-and-forth.
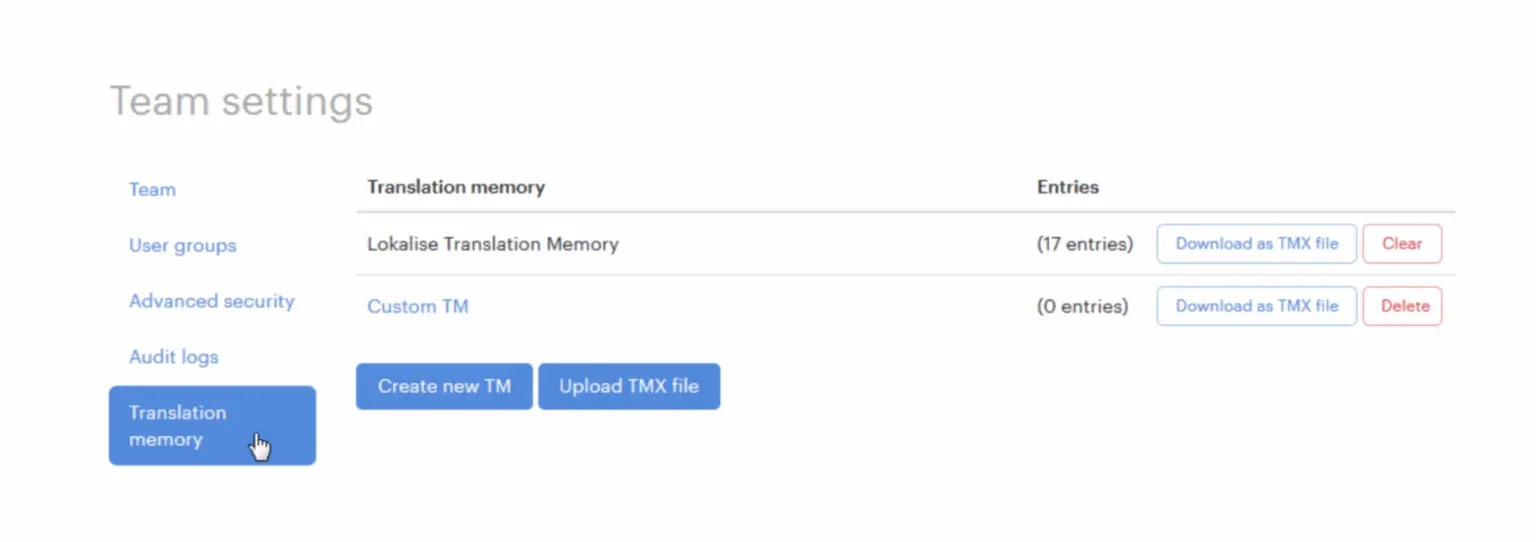
As projects grow, you add new people, and everyone contributes to the growth of the database. In Lokalise, team administrators can manage translation memory (.tmx) files in the team settings under the “Translation memory” tab. These files are the actual storages for your translation memory entries.
Make your translator’s life easier
This translation memory benefit is not discussed as often, but it matters a lot. For a translator, repetitive typing is one of the fastest routes to burnout. By auto-filling known phrases, a TM frees linguists to focus on nuance, tone, and tricky creative copy.
Higher job satisfaction often translates into better quality and lower turnover, which in turn preserves institutional knowledge inside your language team.
Stronger quality control
Every segment in the translation memory carries its approval history. Reviewers can trace who translated and who signed off, and this makes audits simple. In-tool QA checks compare new text against approved terminology, helping you catch errors before they slip into production.
When translation memory matters the most
Translation memory isn’t a silver bullet for every job, but in some workflows it can make a lot of difference.
Whenever content repeats, changes in small bursts, or demands pixel-perfect consistency, TM delivers outsized returns. Here are the situations where it earns its keep.
Rapid-fire product updates
Agile teams ship new builds every week (or every day). Most strings like “Save changes”, “Create account”, reappear with minor tweaks. Translation memory surfaces the approved translation in real time, so linguists edit only the new words. The release notes go live with the sprint.
High-volume content
Legal documents such as T&Cs, privacy notices, compliance docs… All of them demand the exact same phrasing across markets. Translation memory locks each sentence to its verified translation. This eliminates drift and shaves hours off every annual refresh.
UI and microcopy across different platforms
One button label can live in Web, iOS, Android, and a help article. Store it once in your translation memory and reuse it everywhere. Users see a consistent interface, and designers stop chasing stray translations.
💡 Pro tip
Make sure to give your translators and team members sufficient context by showing where and how the translated text will be displayed. This is what in-context translation is all about.
Multilingual marketing campaigns
Launching the same promo in 10 languages? Marketing translation is tough, but you’re tougher with the help of the right translation tools. The benefit of using translation memory is obvious here. TM handles taglines, CTAs, and boilerplate, leaving copywriters free to localize tone and cultural references instead of re-creating the basics.
Working on large projects or with external vendors
When multiple linguists (or agencies) work on the same file set, a shared TM keeps everyone on the same page (quite literally). New contributors ramp up faster, and reviewers spend less time fixing terminology mismatches.
📚 Further reading
Should you outsource your translation project or take it in-house? We gathered opinions from 15 different experts to brings you the most relevant list of pros and cons.
Limitations of translation memory (and how to fix them)
Even the smartest translation memory has its quirks. Leave it unattended and the same tool that speeds you up can start feeding cluttered, off-brand suggestions.
Here’s what to keep an eye out for. We’re keeping it simple and actionable.
A cluttered TM slows everyone down
The issue: Old or low-quality segments pile up, so translators wade through not-as-relevant fuzzy matches.
The fix: Schedule routine clean-ups. Archive segments marked as “obsolete” in your CAT tool and make sure to merge duplicates. For example, Lokalise lets you find, filter, and delete TM entries in the Translation Memory widget or by exporting the TMX file and bulk-deleting entries you don’t need anymore.
Context can get lost
The issue: “Charge” means one thing in a pricing page and another in a battery widget. However, TM treats both strings as the same.
The fix: Make sure to attach proper metadata (e.g., UI location, product area, web page) to each unit. Most tools expose custom fields for this. When metadata is present, the tool can filter suggestions by context before showing them to the linguist.
Low-quality fuzzy matches waste clicks
The issue: A 75 % match often takes longer to fix than translating from scratch.
The fix: The tool is only as good as its user. Raise the minimum match threshold (e.g., 85% or 90%) for automatic suggestions. Anything below that should appear only on request.
Low-quality fuzzy matches waste clicks
The issue: TM stores full sentences, not single terms. This means that “workspace” and “dashboard” can sneak in as inconsistent synonyms.
The fix: Pair your TM with a dedicated termbase or glossary. Most modern translation systems let you surface term matches alongside TM hits.
Style changes over time
The issue: Your brand voice evolves. This means the older segments might sound a bit dated.
The fix: Version your TM. Keep a “V1” archive for history and a “live” memory that’s aligned with the current style guide. When the voice shifts, run a targeted review of high-visibility segments. Then overwrite them in the live TM. Simple as that.
New content with zero matches
The issue: A TM is silent on brand-new topics. This forces translators to start cold.
The fix: Integrate machine translation as a fallback for no-match segments, but pipe MT output through your TM editor. This way, linguists can post-edit and save the polished text back to the memory for next time.
🤖 Feeling skeptical about AI translation?
Although sometimes, AI translation sounds too good to be true, you might want to become more open to what they have to offer. Learn more about the best AI translation tools out there.
Why translation memory is a must-have
When you’re shipping features every sprint and updating copy almost as fast, re-translating identical sentences becomes a bottleneck. A well-maintained translation memory removes a good chunk of it.
TM slashes per-word costs by reusing approved text, and it trims turnaround from days to hours, But the payoff goes beyond speed and savings.
Take a minute to think about it, and you’ll see that translation memory turns localization into a compounding asset. Each new project enriches the database, which then accelerates the next release, which feeds the memory again.
Now pair that virtuous loop with smart maintenance. Occasional clean-ups, clear metadata, and a glossary for key terms, nothing too demanding. What you get is a system that scales effortlessly from one language to ten.
Mia has 13+ years of experience in content & growth marketing in B2B SaaS. During her career, she has carried out brand awareness campaigns, led product launches and industry-specific campaigns, and conducted and documented demand generation experiments. She spent years working in the localization and translation industry.
In 2021 & 2024, Mia was selected as one of the judges for the INMA Global Media Awards thanks to her experience in native advertising. She also works as a mentor on GrowthMentor, a learning platform that gathers the world's top 3% of startup and marketing mentors.
Earning a Master's Degree in Comparative Literature helped Mia understand stories and humans better, think unconventionally, and become a really good, one-of-a-kind marketer. In her free time, she loves studying art, reading, travelling, and writing. She is currently finding her way in the EdTech industry.
Mia’s work has been published on Adweek, Forbes, The Next Web, What's New in Publishing, Publishing Executive, State of Digital Publishing, Instrumentl, Netokracija, Lokalise, Pleo.io, and other websites.
Mia has 13+ years of experience in content & growth marketing in B2B SaaS. During her career, she has carried out brand awareness campaigns, led product launches and industry-specific campaigns, and conducted and documented demand generation experiments. She spent years working in the localization and translation industry.
In 2021 & 2024, Mia was selected as one of the judges for the INMA Global Media Awards thanks to her experience in native advertising. She also works as a mentor on GrowthMentor, a learning platform that gathers the world's top 3% of startup and marketing mentors.
Earning a Master's Degree in Comparative Literature helped Mia understand stories and humans better, think unconventionally, and become a really good, one-of-a-kind marketer. In her free time, she loves studying art, reading, travelling, and writing. She is currently finding her way in the EdTech industry.
Mia’s work has been published on Adweek, Forbes, The Next Web, What's New in Publishing, Publishing Executive, State of Digital Publishing, Instrumentl, Netokracija, Lokalise, Pleo.io, and other websites.
5 Best Translation Management Systems to Make Projects Easy
The traditional translation management system (TMS) is dead. It doesn’t support the many moving parts of the multilingual content lifecycle, such as managing linguistic assets and syncing with design systems to integrating with codebases, automating QA, and coordinating stakeholders across functions. Modern TMS solutions go far beyond translation. They bring together translators, developers, marketers, and designers under one roof. But with dozens of transla