In this article, we’ll explore various types of character encoding used in the world of information technology. We’ll break down why encoding matters, explain how they function, and highlight the key differences between ASCII, UTF-8, UTF-16, and the Unicode Standard. Understanding these differences is essential for correctly handling text in any software application, especially when working with localized time and date formats that rely on proper character representation.
We humans communicate using natural languages like English, French, and Japanese. Naturally, when we use computers for our daily tasks, we expect to continue using these languages. For instance, you might start your day by opening a work chat to discuss the day's tasks with colleagues located around the globe.
But computers don’t actually "understand" language. At their core, they work with simple numbers and binary data. They need a way to translate human language into something they can process — and that’s where character encoding comes in.
CPUs and binary format
Inside your computer, one or more central processing units (CPUs) execute instructions in binary. Picture a long tape filled with commands: fetch this number, add it to another number, double the result, and so on. CPUs can also "jump" to different parts of this tape for specific instructions. The core process is straightforward and has stayed the same for decades.
So, what exactly is "binary"? Simply put, it's all about zeros and ones (representing false and true, or no and yes). All those binary digits are grouped into chunks called bytes — typically 8 bits at a time. Even in today’s complex systems, with AI and modern software, the hardware still runs on simple binary logic.
The problem is, we don’t speak in binary — and computers don’t understand natural language. That’s why character encoding exists: to translate human-readable text into something machines can process. It might sound simple (we’ve had things like Morse code for a long time), but text encoding has its own set of challenges. Let’s look at how different encoding types handle this.
Text encoding types
Text encoding is all about converting letters, numbers, and symbols into a format computers can understand — usually as binary data. Over the years, different encoding systems have been created to handle different languages, symbols, and use cases.
Here are the main types you’ll come across:
ASCII – one of the earliest standards, focused on English characters and basic symbols.
Extended ASCII / ANSI – regional or platform-specific extensions of ASCII, used mostly before Unicode.
Unicode – a global standard that assigns a unique code to every character, across all writing systems. It’s not an encoding itself but a big list of characters with assigned numbers (called code points).
UTF-8 – an encoding format for Unicode that uses 1 to 4 bytes per character. It’s compact and backwards-compatible with ASCII.
UTF-16 and UTF-32 – other Unicode encoding formats, using 2 or 4 bytes per character, depending on the version.
Each of these has its own strengths, limitations, and use cases. Let’s break them down, starting with ASCII.
ASCII character encoding
Forty years ago, the IT world was simpler. Hardware wasn't as powerful, software wasn't as complex, and personal computers weren’t common in most countries. Most programming was done in English, and a lot of IT development was happening in the US.
Because of that, the focus was on how to represent English letters and basic symbols — like punctuation marks and brackets — in a way that computers could handle. The result was ASCII: the American Standard Code for Information Interchange.
How ASCII character encoding works
ASCII (American Standard Code for Information Interchange) was introduced in the 1960s for teletypes. The idea is simple: assign a number to each character. For example, the letter "A" gets the number 65, "B" gets 66, and so on.
Since computers work with binary, these numbers can be easily converted into binary format — making it easy for machines to store and process text.
ASCII uses numbers from 0 to 127. Here’s how it breaks down:
0–31 – control characters (not printable). These were originally based on typewriter functions, like:
8 → backspace
10 → new line
13 → carriage return
32–127 – printable characters, including:
32 → space
40 → (
65 → A
70 → F
97 → a
102 → f
Uppercase and lowercase letters have different codes — so "A" and "a" are not the same in binary.
Even though typewriters are long gone, some of their commands are still with us. For example, the carriage return (code 13) and new line (code 10) are still used in text files and programming.
That’s why when you open a file on different systems (like Windows vs Linux), line breaks might behave differently — they don’t always agree on how to use those old codes.
It's all about bits
So, ASCII uses numbers from 0 to 127. What does that tell us? It means every character can be stored using just 7 bits.
Let’s break that down:
1 bit can hold two values: 0 or 1
So with 7 bits, you get 2**7 = 128 possible values
Since we count from 0, the highest value is 127
Even if you're not into math, just remember: all standard ASCII characters fit into 7 bits — and that’s a big deal.
But here’s the thing: 7 bits isn’t super convenient.
It’s an odd number (literally)
Computers have long been fine working with 8 bits, which makes 1 byte
So developers thought: why not just use the full byte?
Let’s update the math:
8 bits → 2**8 = 256 values
That gives a range from 0 to 255
Now we’re talking! Just by adding one extra bit, we almost double the capacity. And since ASCII already used up 0 to 127, the codes from 128 to 255 were wide open. Thus, these "free" codes can be used to fulfill your wildest fantasies…
That opened the door for all kinds of extended characters — which we’ll get into next.
It's a wild, wild world
So, we had this neat little space from 128 to 255 — perfect for adding more characters to fulfill our fantasies. But as you know people tend to have different fantasies. In other words, different systems used those extra codes in different ways.
Back in the day, PC manufacturers didn’t agree on what these "extra" codes should represent. For example:
IBM PCs used codes 128–255 for:
Line-drawing symbols
Math signs like √
Latin letters with accents (é, ñ, etc.)
But elsewhere, like in the USSR, computers had different ideas. They used those same codes to display Cyrillic characters instead.
What could possibly go wrong?
Let’s say it’s the 1980s. You’re in the US on an IBM PC. You write something like: "I went to the café."
You send it to a colleague in the USSR. He opens the file on a local machine using a different encoding. What happens?
The word "café" may show up as "cafу"
That last letter isn’t a typo — it’s actually a Cyrillic letter "у", which sounds like “oo”
Why? Because that machine uses an encoding like KOI-8, which keeps codes 0–127 the same as ASCII, but uses 128–255 for Cyrillic letters.
Same numbers, different meanings
Here’s a tiny table to show what’s going on:
Code
IBM PC (US)
KOI-8 (USSR)
233
é
У (Cyrillic "U")
241
ñ
п (Cyrillic "p")
247
÷
щ (Cyrillic "shch")
Same number, totally different symbols.
So what's the problem?
Well, we suddenly can’t trust those extra codes. Text might look fine on one machine and totally broken on another. Everyone’s fantasy character set was clashing with everyone else’s.
To fix this mess, the industry needed a better solution — something consistent, flexible, and global.
ANSI code pages
To deal with the mess of different machines interpreting extra character codes in their own way, engineers at the American National Standards Institute (ANSI) stepped in. They proposed a standardized approach to how codes 128–255 should be handled — leading to the idea of code pages.
The code page idea
The concept was simple:
Codes 0–127 stay the same everywhere (standard ASCII).
Codes 128–255 get different meanings depending on the code page used.
A code page is just a lookup table that tells the computer: “this number means that character.”
A few well-known ANSI code pages
Here are some examples of ANSI code pages used in different regions:
Code page
Region / Language
Example mapping
1252
Western Europe (Windows)
241 → ñ (Spanish)
1251
Cyrillic (Russia, Ukraine)
241 → п (Cyrillic "p")
1253
Greek
182 → Ψ
One of the most popular was CP-1252 (Windows-1252), released with Windows 3.1 in 1992. It was designed for English and other Western European languages like Spanish, French, and Portuguese.
On paper, this looked like a neat solution. You could support different languages by simply switching the code page. But in reality, this created a new problem — because unless two systems used the exact same code page, the text could still get messed up.
We’ll get into those headaches in the next section.
Problems with code pages
Code pages were a step forward, but they came with serious limitations — especially as computing became more global.
One code page at a time
The first issue: you could only have one active code page on a system at a time. So if you wanted to work with multiple languages — like Greek and Serbian — you had a problem. Switching between code pages wasn’t smooth, and combining different scripts in the same document was a mess unless you used some weird workarounds.
Too many characters, not enough codes
The second issue hit harder in Asian countries. Languages like Chinese and Japanese use thousands of characters — way more than the 128 extra spots available in a single code page.
To work around this, some systems used multi-byte encoding:
Common characters used 8 bits (1 byte)
Complex ones used 16 bits (2 bytes)
This helped fit more symbols, but introduced a new headache: "How do you know how many bytes a character takes?". This made simple things — like moving backwards through a line of text — a lot trickier.
A global world needs a global standard
Then came the internet. People started sending documents across borders, and suddenly, code page mismatches became a daily problem. Characters would show up as gibberish, and nobody knew what was going on.
It became clear: the world needed a unified, consistent system for handling text — no matter the language, region, or platform.
And that’s where Unicode steps in.
The Unicode standard
In the early 1990s, specialists introduced a new standard called Unicode. The goal was simple but bold: create a universal set of characters that any computer, anywhere in the world, could understand — no matter the language or location.
For the first time, a computer in the US could share a document with one in Japan or Egypt, and all the characters would show up exactly as intended. Unicode became a kind of global translator, making it possible to write and read texts in any language — from English and Russian to Arabic, Chinese, and even modern symbols like emojis — without worrying about code pages or mismatched encodings.
Representing characters: Not all "A"s are the same
Unicode had to solve a much more complex problem than ASCII — because the world’s languages are wildly diverse. So let’s break this down a bit.
To us humans, it’s obvious that:
"A", "B", and "C" are different letters
"A" and "a" are also different
And even though the Cyrillic letter "А" looks just like the Latin "A", it’s actually a completely different character
But at the same time:
The letter "A" in bold, italics, or in a different font (like Arial vs Helvetica) is still the same character — just styled differently
So styling isn’t part of the character itself — it’s more like decoration
But sometimes the "extra stuff" matters! You can’t always ignore accents or diacritics. Take these examples:
"e" is not the same as "é" — especially in French or Spanish
"ß" in German isn’t a fancy "B" — it means "ss"
In Latvian, "ķ" isn’t just a stylized "k" — it’s a separate letter entirely
For example, the Latvian word for "cat" is "kaķis". Write it as "kakis", and locals might laugh — because now it sounds like something very different.
And that’s just one language. Now imagine handling scripts like Arabic, Chinese, or Hindi — where shape, direction, and context can all affect how a character looks and what it means.
This is why Unicode had to be way more than just a list of letters. It had to carefully define what each character is — including:
Letters with accents
Letters from different scripts that look similar
Special symbols with specific meanings
Punctuation, emojis, and more
So yeah, the inventors of Unicode weren’t just building a bigger version of ASCII. They were solving a global language puzzle.
How Unicode works
Code points
In Unicode, every character, symbol, or emoji is assigned a unique code point. A code point looks like this:
U+1234 → where "U" stands for Unicode, and the number is written in hexadecimal (base-16)
These values are easy to convert to binary, which makes them efficient for computer processing. You can look up code points for just about anything on the official Unicode website.
Here are a couple of examples:
U+0041 → the Latin letter "A"
U+1F60A → 😊 (a smiling face)
ASCII compatibility?
Wait a sec — didn’t we say earlier that in ASCII, the letter "A" is 65?
Yes! But remember:
Unicode uses hex (base-16)
ASCII uses decimal (base-10)
So if you convert 0x41 (hex) to decimal, guess what? You get 65. That means many basic characters keep the same numeric values across both systems — which helps with backward compatibility.
But it’s not just ASCII
So far, Unicode might sound like just a bigger ASCII list. But here's where it gets interesting.
Unicode supports character composition — meaning you can build characters using multiple code points.
Example:
U+0065 → "e"
U+0301 → combining acute accent
Together: "é"
This combo produces the same visual result as using a single precomposed character:
U+00E9 → "é" (prebuilt version)
And you’re not limited to just one modifier — Unicode allows stacking multiple diacritics to build more complex characters if needed.
The Unicode standard defines over 1 million possible code points, though not all are used yet. It covers:
All modern writing systems
Ancient scripts
Math symbols
Emojis
Even fictional alphabets (yep, Klingon is in there)
But there's a catch...
Unicode doesn’t say how to store or send these code points in memory or over the internet. It just defines the values — not the encoding.
So how do we actually use Unicode in real software? That’s where UTF-8, UTF-16, and UTF-32 come in — they’re encoding formats that implement the Unicode standard in different ways.
UTF-16 character encoding
UTF-16 (sometimes called UCS-2) was the first encoding proposed to store Unicode text. The idea was simple: use 16 bits (2 bytes) for every character. That's actually why it’s called UTF-16, duh.
So if you want to store a character like the Latin letter "A" (U+0041), you just write it using two bytes: 00 41. Simple, right?
Let’s try a quick example. The word “cat” has these code points:
U+0063
U+0061
U+0074
Using UTF-16, these would be stored in memory like this:
00 63 00 61 00 74
Looks neat. But here’s where things get a little more complicated.
Endianness
When writing these bytes to memory, we can actually flip the order of the two halves. So instead of 00 63, we might write 63 00. This choice depends on the computer’s endianness — a system-level detail that decides how multi-byte values are stored.
These terms come from Jonathan Swift’s Gulliver’s Travels, believe it or not — worth a read if you're in the mood for some 18th-century satire.
From a theoretical perspective, it has no impact on how to represent our bytes: from left to right or from right to left. However, some computer architectures historically use "big-endian", whereas some use "little-endian". Don't ask me why, it's a long story that is not directly related to today's topic. The fact is that different CPUs might use different "endianness" (however, there are also processors that can work in both modes).
But that raises a problem: how can you tell what endianness was used in a UTF-16 file? To solve this, a special marker called the byte order mark (BOM) was introduced. It’s placed at the beginning of the file and can be:
FE FF → big-endian
FF FE → little-endian
It’s just two bytes in hexadecimal, but it tells the computer how to read the rest of the file correctly.
Too many zeros!
Okay, now let’s take a second look at our “cat” string:
00 63 00 61 00 74
Each character includes a whole extra byte filled with zeros. And that feels wasteful — especially for languages that only use basic Latin characters. Why store 00 41 for "A" when ASCII just uses 41?
This adds up fast, especially in programming, where English text is used all over the place — in code, file names, configuration files, you name it. UTF-16 doubles the storage needs for no real gain in these cases.
Compatibility problems
There’s another issue. Even though Unicode keeps the same code numbers as ASCII for characters like "A" (which is 65), UTF-16 isn’t directly compatible with ASCII. ASCII uses 8-bit values, but UTF-16 forces every character into 16 bits.
So in ASCII, you’d store "A" as 41, but in UTF-16, it has to be 00 41. It’s not the same binary data, which means old ASCII documents had to be converted — and a lot of people weren’t excited about that.
Not enough room
And then there's the biggest limitation: 16 bits can only store (2 ** 16) - 1 = 65 536 characters. That sounds like a lot, but Unicode now defines over a million code points. That means UTF-16 needs special tricks (like surrogate pairs) to represent characters beyond that limit — and that breaks the original "every character takes 2 bytes" promise.
The result?
UTF-16 turned out to be a bit awkward. It used more space than needed for English text, wasn’t fully backward-compatible with ASCII, and eventually needed workarounds to support all of Unicode. So while it did see some use (especially in early Windows systems and Java), it never became the universal solution.
Still, it paved the way for something better — a format that solved these problems while staying compact and compatible. That format is UTF-8.
UTF-8 character encoding
In the early 2000s, a new encoding format called UTF-8 was introduced. Like UTF-16, it followed the Unicode Standard — but it approached the problem in a much smarter, more flexible way.
Let’s get one thing straight right away: UTF-8 is not the same as Unicode. Unicode is the list of characters and their code points. UTF-8 is one way to store those characters using bytes. Think of it as a way to pack all the stuff from the Unicode table into real files and memory — efficiently.
The byte-based approach
As the name suggests, UTF-8 uses 8-bit blocks — also called octets or just bytes. The clever bit is that it uses a variable number of bytes per character, depending on the code point:
Characters from U+0000 to U+007F (0 to 127) take 1 byte
Characters from U+0080 to U+07FF (128 to 2047) take 2 bytes
Characters from U+0800 to U+FFFF take 3 bytes
Characters from U+10000 to U+10FFFF take 4 bytes
This setup lets UTF-8 encode the full range of Unicode characters — over a million code points — using no more than 4 bytes per character.
ASCII-compatible by design
Here’s where it gets really cool: code points from 0 to 127 match standard ASCII exactly. So, for example:
The character "A" (U+0041) is stored as 41
The character "%" (U+0025) is stored as 25
In other words, valid ASCII files are already valid UTF-8 files. No conversion needed, no wasted space. This solves the problem that UTF-16 had — where every character, even simple ones, took two bytes with a bunch of extra zeros.
Byte patterns in UTF-8
UTF-8 follows specific binary patterns to mark how many bytes a character takes. Without getting too deep into bit-level stuff, here's the general idea:
Bytes
Range
First byte pattern
Example character
1
U+0000–U+007F
0xxxxxxx
A, a, $, #
2
U+0080–U+07FF
110xxxxx 10xxxxxx
é, ñ
3
U+0800–U+FFFF
1110xxxx 10xxxxxx 10xxxxxx
ש (Hebrew shin)
4
U+10000–U+10FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
🐱 (cat emoji)
Each extra byte starts with 10, so a computer can easily tell where a character starts and where it continues.
Why UTF-8 won?
Let’s recap what makes UTF-8 awesome:
Efficient for English and other ASCII-based texts — no wasted space
Compatible with existing systems (ASCII files, old protocols, etc.)
Flexible — supports all languages and symbols, including emojis
Stream-safe — characters can be identified and decoded even in long streams of text
No endianness issues — it’s just a stream of bytes, always in the same order
It basically checked every box that earlier encodings (like UTF-16 or ANSI code pages) couldn’t.
Because of that, UTF-8 quickly became the default encoding for the web, modern software, and even entire operating systems. Today, it’s safe to say that UTF-8 is the de facto global standard for text encoding.
UTF-7 was designed for systems that could only handle 7-bit data, like some early email protocols. It avoids using the highest bit entirely, which made it a workaround for old-school messaging systems that might strip or mishandle anything beyond ASCII. It’s rare today and mostly obsolete.
UTF-32 takes the opposite approach — it uses a fixed 4 bytes (32 bits) for every character, no matter what. This makes it super simple for computers to process, since every character takes the same amount of space. But it’s very inefficient for everyday text, especially when most characters could fit in 1 or 2 bytes. For this reason, UTF-32 is mostly used in internal systems or special cases where simplicity matters more than space.
Encoding, encoding everywhere!
By now, you’ve probably realized there are lots of different text encodings out there — and it's very important to know which one your data is using. Even something as basic as a plain text file is still encoded in some way.
If you have text but don’t know the encoding, it’s basically useless — because you can’t safely interpret what each byte means.
The web example
On web pages, we usually declare the encoding like this:
<meta charset="utf-8">
This tells the browser, “Hey, decode everything using UTF-8.” But if this tag is missing or incorrect, things can break.
Let’s say your HTML is written in UTF-8, but the browser tries to read it as CP-1252 (an old Windows encoding). Characters like é, ñ, or — might show up as garbage or get replaced with question marks. Why? Because there's no 1-to-1 mapping between certain characters in those encodings.
The funny paradox
You might ask: “Wait… if the encoding info is in the file, how does the browser even start reading it?”. To read the encoding, you need to read the file — but to read the file, you need the encoding. Classic chicken-and-egg situation.
Luckily, this problem is handled pretty well in practice:
The <meta charset> tag is usually near the very top of the HTML
That part of the file is often written in plain ASCII (Latin letters, brackets, quotes), which nearly all encodings can interpret correctly
The browser starts reading in a safe fallback mode (like cp1252), finds the actual encoding, then switches over as needed
Outside the web
This isn’t just a browser thing. You’ll run into encoding declarations in:
Emails (they have headers like Content-Type: text/plain; charset=utf-8)
APIs and web servers (where the Content-Type header tells clients how to decode text)
Programming languages and IDEs (which often default to UTF-8 but let you pick others)
And when encoding isn’t specified? Software might guess — and guessing is risky. You might get lucky… or end up with weird symbols, broken layouts, or even corrupted data.
The takeaway
Always declare your encoding, my friend, especially when sharing or storing text across systems. It’s like telling someone what language you're speaking — without it, no one knows how to understand you.
Common encoding issues
Even with modern standards like UTF-8, encoding problems still happen — especially when dealing with older systems, mismatched settings, or copy-pasting from weird sources. Here are a few common issues you might run into:
1. Garbled characters or question marks
You load a document or a web page, and instead of proper letters, you see something like:
This usually means the text was encoded in one format (like UTF-8) but read as something else (like CP-1252 or ISO-8859-1). The bytes are correct, but the interpretation is wrong.
2. Copy-paste fails
You copy some text from one app and paste it into another — and suddenly, weird symbols appear. This often happens when the source and target programs use different encodings or don’t support certain characters.
3. Misinterpreted file content
A file looks fine on one machine but breaks on another. That’s usually because the file doesn’t declare its encoding, and different software tries to "guess" how to read it. Spoiler: guessing often fails.
4. Mixing encodings in the same file
This is rare but dangerous. Some old systems might stitch together parts of different encodings — like combining ASCII with a localized code page or a legacy script. This can completely break processing or display logic.
5. BOM-related issues
If a file starts with a byte order mark (BOM) — like in UTF-16 — and a program doesn’t expect it, you might see random characters at the beginning of the text ( is a classic one). Some tools strip the BOM, some don’t, and some just show it as junk.
Text encoding cheat sheet
A quick-reference guide to keep your text files clean, readable, and compatible.
Basic concepts
Encoding: Turning characters into bytes
Unicode: The global character set
UTF-8 / UTF-16 / UTF-32: Ways to encode Unicode characters
Question marks (?) or replacement boxes → Unsupported characters
Best practices
Use UTF-8 unless you have a very good reason not to
Always declare encoding in HTML, emails, APIs, etc.
When sharing files, make sure the other side knows the encoding
Avoid mixing encodings — stick to one per file
Watch out for copy-paste from unknown sources — especially from PDFs or Word files
Conclusion
We’ve taken a solid tour through the world of text encoding — from the early days of ASCII to the global reach of Unicode and its many encoding formats like UTF-8, UTF-16, and UTF-32. Along the way, we’ve seen just how important encoding is for making text readable, shareable, and reliable across different systems and languages.
Thanks for sticking around — and hopefully, next time you see a question mark where a letter should be, you’ll know exactly why.
Ilya is the lead for content, documentation, and onboarding at Lokalise, where he focuses on helping engineering teams build reliable internationalization workflows. With a background at Microsoft and Cisco, he combines practical development experience with a deep understanding of global product delivery, localization systems, and developer education.
He specializes in i18n architectures across modern frameworks — including Vue, Angular, Rails, and custom localization pipelines — and has hands-on experience with Ruby, JavaScript, Python, Elixir, Go, Rust, and Solidity. His work often centers on improving translation workflows, automation, and cross-team collaboration between engineering, product, and localization teams.
Beyond his role at Lokalise, Ilya is an IT educator and author who publishes technical guides, best-practice breakdowns, and hands-on tutorials. He regularly contributes to open-source projects and maintains a long-standing passion for teaching, making complex internationalization topics accessible to developers of all backgrounds.
Outside of work, he keeps learning new technologies, writes educational content, stays active through sports, and plays music. His goal is simple: help developers ship globally-ready software without unnecessary complexity.
Ilya is the lead for content, documentation, and onboarding at Lokalise, where he focuses on helping engineering teams build reliable internationalization workflows. With a background at Microsoft and Cisco, he combines practical development experience with a deep understanding of global product delivery, localization systems, and developer education.
He specializes in i18n architectures across modern frameworks — including Vue, Angular, Rails, and custom localization pipelines — and has hands-on experience with Ruby, JavaScript, Python, Elixir, Go, Rust, and Solidity. His work often centers on improving translation workflows, automation, and cross-team collaboration between engineering, product, and localization teams.
Beyond his role at Lokalise, Ilya is an IT educator and author who publishes technical guides, best-practice breakdowns, and hands-on tutorials. He regularly contributes to open-source projects and maintains a long-standing passion for teaching, making complex internationalization topics accessible to developers of all backgrounds.
Outside of work, he keeps learning new technologies, writes educational content, stays active through sports, and plays music. His goal is simple: help developers ship globally-ready software without unnecessary complexity.
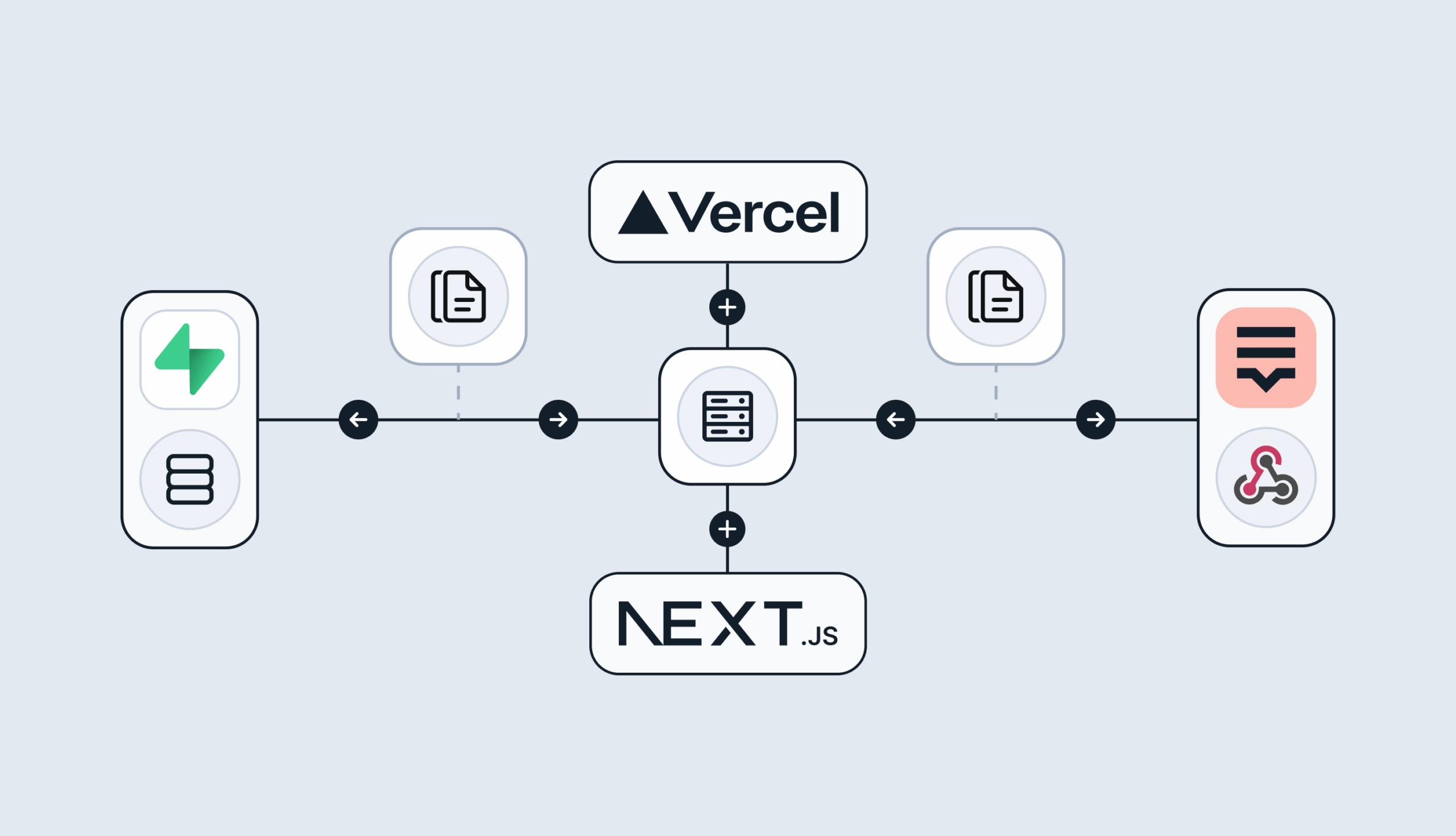
Build a smooth translation pipeline with Lokalise and Vercel
Internationalization can sometimes feel like a massive headache. Juggling multiple JSON files, keeping translations in sync, and redeploying every time you tweak a string… What if you could offload most of that grunt work to a modern toolchain and let your CI/CD do the heavy lifting? In this guide, we’ll wire up a Next.js 15 project hosted on Vercel. It will load translation files on demand f
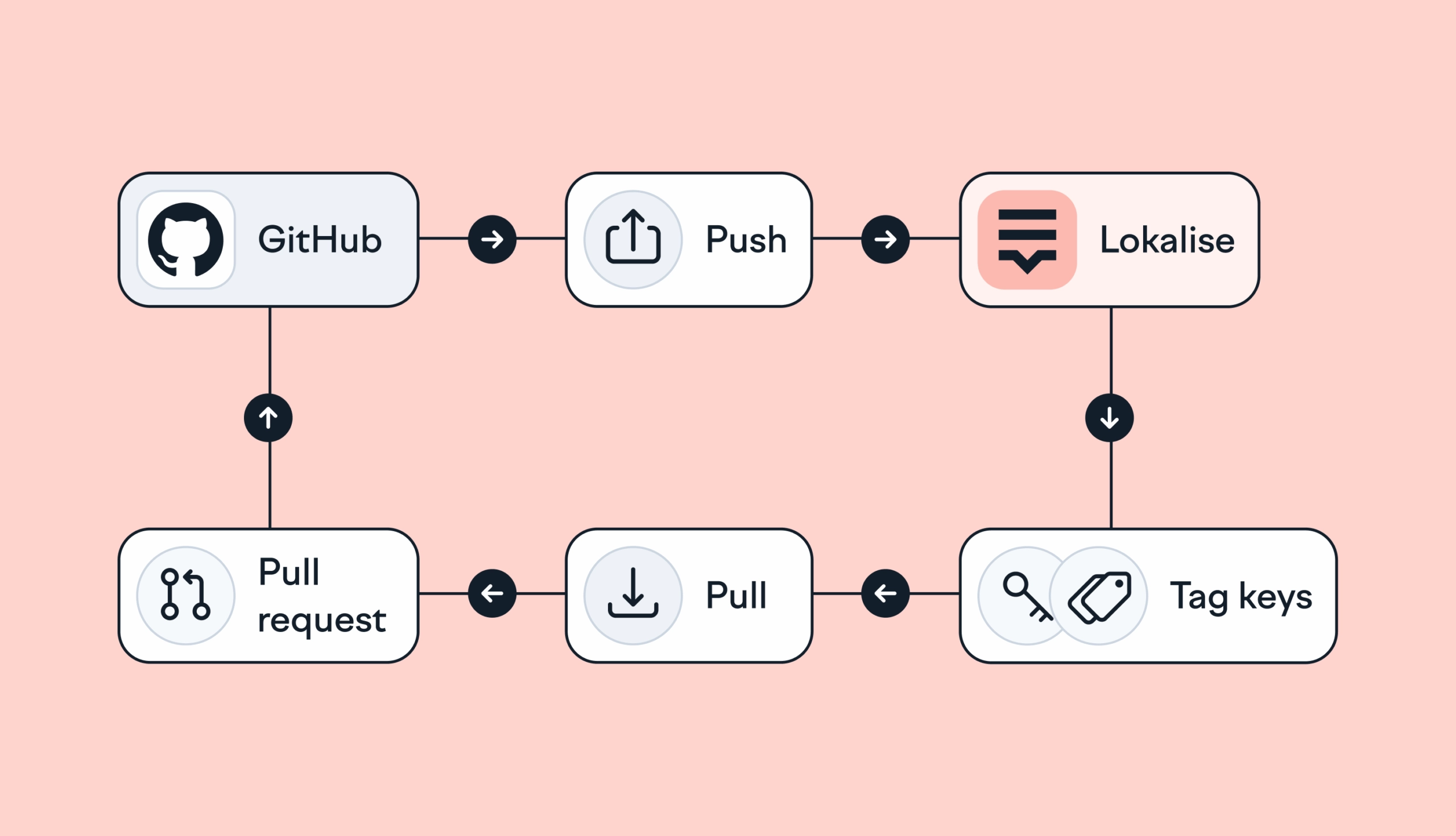
Hands‑on guide to GitHub Actions for Lokalise translation sync: A deep dive
In this tutorial, we’ll set up GitHub Actions to manage translation files using Lokalise: no manual uploads or downloads, no reinventing a bicycle. Instead of relying on the Lokalise GitHub app, we’ll use open-source GitHub Actions. These let you push and pull translation files directly via the API in an automated way. You’ll learn how to: Push translation files from your repo to LokalisePull translated content back and open pull requests automaticallyWork w