Before neural networks took over, machines learned to translate by looking at patterns in large sets of human-translated texts. This approach is called Statistical Machine Translation (SMT). It was a turning point in the history of language technology.
Truth be told, Statistical Machine Translation might not be the leading approach today, but it played a crucial role in shaping the tools we now take for granted.
Understanding how it works gives you a deeper view of how machines have evolved in handling language (and why translation is such a complex task in the first place).
🤖 Learn more about machine translation
If you’re curious to learn more about machine translation, LLMs, and the role AI plays in the localization industry, make sure to bookmark the Lokalise Blog. We’re continuously publishing new stories that help you stay at the forefront of the newest language tech trends.
What is statistical machine translation (SMT)?
Statistical machine translation (SMT) is one of the earliest methods machines used to translate language at scale. It doesn’t rely on grammar rules. It doesn’t understand meaning. Instead, it uses data, and lots of it.
Here’s how it works in simple terms. SMT looks at thousands (or millions) of example translations. It doesn’t try to figure out what words mean. It just looks for patterns.
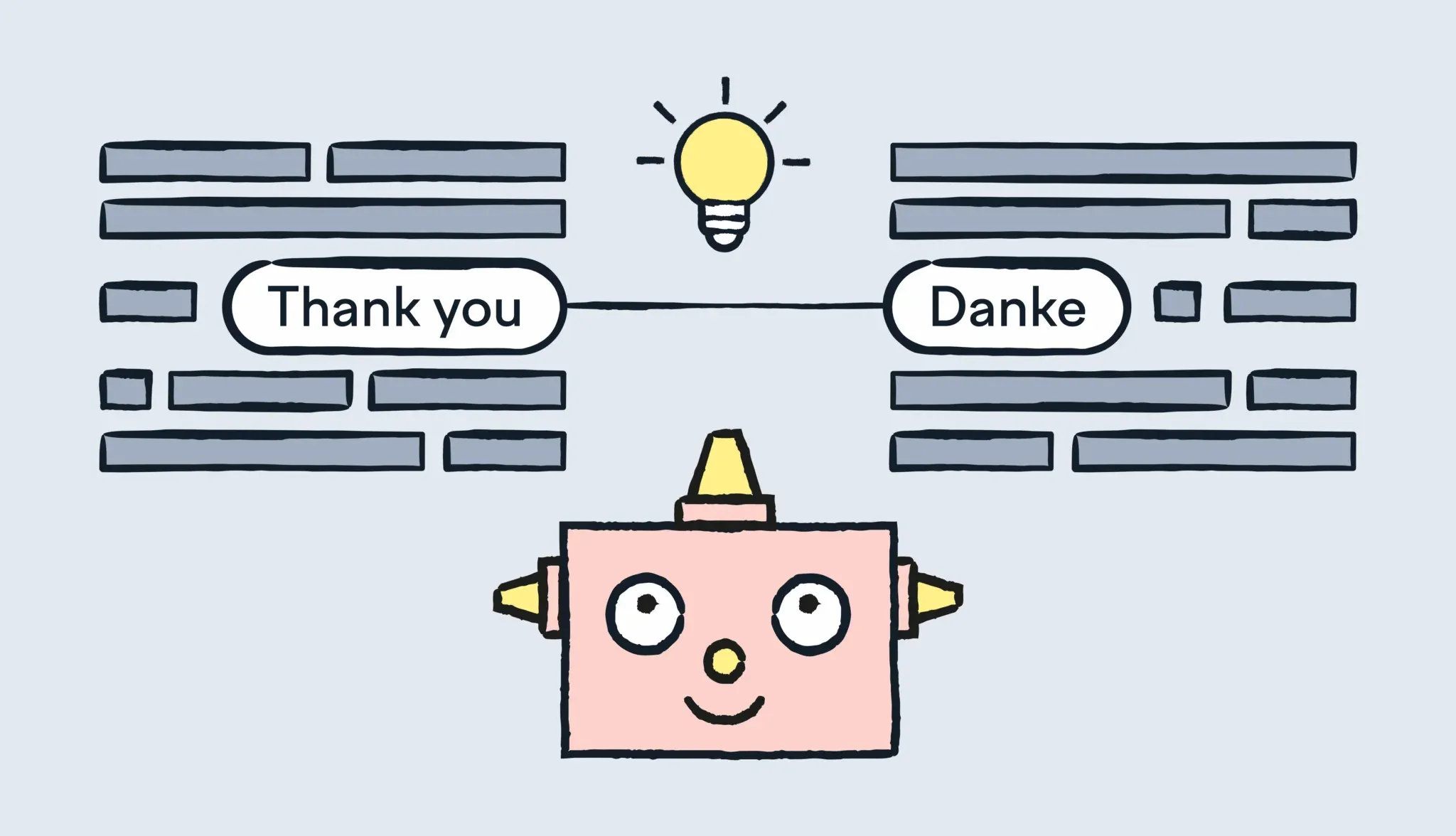
If the English phrase “Thank you” regularly shows up alongside the German “Danke”, the system starts to connect the dots. It learns that “Danke” is a good bet when it sees “Thank you” again.
What makes SMT powerful is that it learns from real human translations. It doesn’t need to be hand-coded with rules. Just give it the data, and it builds its own statistical model of how languages line up.
Before SMT, translation systems were built by linguists writing rules for every verb, noun, and sentence structure. Imagine how much time that took? Plus, it couldn’t scale well.
SMT offered a faster, more flexible way to build translation systems, especially for language pairs with enough training data.
⏩ The technology that brought us to the place we are today
Even though it’s been largely replaced by neural machine translation (NMT), SMT was a huge step forward. It made machine translation faster, more accessible, and more adaptable.
And if you’re trying to understand how we got to today’s AI-driven tools, SMT is where the modern story begins. Read more about translation technology advancements and where we’re heading next.
What is SMT translation model
So, how does SMT actually automatically translate one sentence from one language into another?
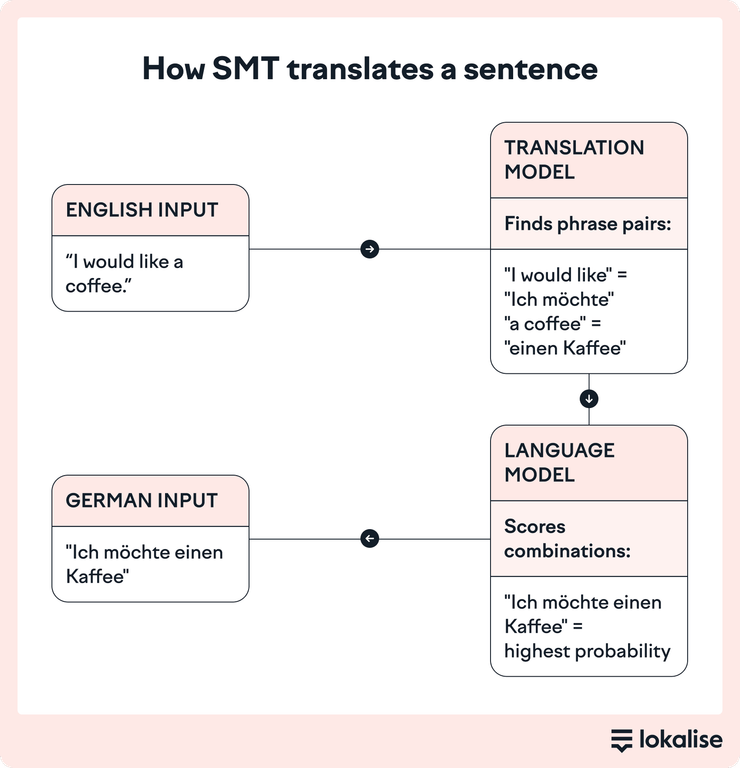
It all comes down to two core components. On one side, you have the SMT translation model, and on the other, the language model.These two work together to figure out not just what to say, but how to say it in the target language.
1. The translation model = matching meanings between language pairs
The translation model looks at how words or phrases in one language typically map to another. It’s built by analyzing massive bilingual datasets. So, it looks at the texts that already exist in both languages, like subtitles, manuals, or documents.
This model doesn’t just match individual words. It works at the phrase level, which helps avoid awkward, literal translations.
But that only gets us halfway.
2. The language model = ensuring the translation sounds natural
Once the translation model suggests possible outputs, the language model steps in to smooth things out.
Its job is to make sure the final sentence sounds natural in target language. It does this by learning how native speakers actually talk, based on large monolingual texts written in the target language.
Let’s look at English-German translations. The translation model might recognize a few possible options for “I would like a coffee”, like:
“Ich möchte einen Kaffee”
“Ich will Kaffee haben”
“Ich hätte gern einen Kaffee”
But then, the language model scores these based on how often they appear in real German sentences. It picks the one that sounds most fluent and idiomatic, so likely “Ich möchte einen Kaffee”.
🗒️ Key takeaway
When it comes to the statistical machine translation, you should remember two things:
– The translation model figures out what to say – The language model ensures it sounds right in the target language
SMT tries different combinations and picks the sentence with the highest overall probability. It’s sort of like a statistical balancing act. And while it’s no longer cutting-edge, this dual-model setup was a major leap forward in machine translation.
Variants of statistical machine translation
Early SMT worked, but not always well. Translating word by word often led to clumsy sentences. To fix that, different versions of SMT were created. Each one was designed to handle language a bit more intelligently.
1. Word-based SMT
Word-based was the earliest form of SMT. It treats sentences as a sequence of individual words and tries to translate each one based on probability.
For example, if the system sees “House” often translated into German as “Haus”, it will assume that’s the best option.
But word-based SMT struggles with word order and context.
It might translate “I am going to the store” as “Ich bin gehe zum Geschäft”, a sentence that doesn’t sound right in German. That’s because German uses different grammar rules and word order, which word-based SMT doesn’t handle well.
2. Phrase-based SMT
To improve on that, phrase-based SMT looks at short sequences of words, not just single ones. These “phrases” don’t have to match grammatical rules. They’re just word chunks that often appear together.
Instead of translating “to the store” word by word, it sees it as one unit and matches it to “zum Geschäft.” This results in more natural, accurate translations.
Phrase-based SMT became the dominant approach for many years. It was used in tools like early versions of Google Translate.
🧠 How accurate is Google Translate?
Can you trust Google Translate? Read our research to discover if Google Translate is accurate, and what other alternatives can you explore.
3. Syntax-based SMT
This statistical machine translation version takes grammar into account. It tries to understand the structure of a sentence (e.g., subject, verb, and object), and uses that to guide the translation.
For example, German often places verbs at the end of a sentence. Syntax-based SMT can learn that “I know that he is coming” should become “Ich weiß, dass er kommt” (not “Er ist kommt”).
While more complex, syntax-based models produce better results for language pairs with very different grammar rules.
4. Hierarchical and tree-based SMT
Hierarchical and tree-based SMT models take things a step further than phrase-based or syntax-based SMT. Instead of just looking at phrases or grammar rules, they break sentences down into tree structures.
It’s sort of like a map that shows how each part of the sentence connects.
This structure helps the system understand more than just word order. It sees which words belong together, which phrases depend on others, and how to reassemble them in the target language.
For example, the English sentence “The book that I gave you yesterday is on the table” has several parts that depend on each other.
A tree-based SMT system can recognize that “that I gave you yesterday” is describing the book, and it knows how to rebuild that relationship in German:
“Das Buch, das ich dir gestern gegeben habe, liegt auf dem Tisch.”
💡 Good to know
Without the tree structure, SMT can easily get confused, especially with longer sentences. Verbs end up in the wrong place, clauses get jumbled, and the meaning can shift. But once you introduce tree structures, things click into place.
Remember diagramming a sentence back in school? Well, it works in a similar way. The model sees how each part connects and reassembles the sentence correctly, even when German sends the verb all the way to the end (as it loves to do).Want to learn more? Read about other types of machine translation.
What is the difference between SMT and NMT?
Statistical machine translation (SMT) and neural machine translation (NMT) both aim to do the same thing. They translate text from one language to another. But how they do it is fundamentally different.
SMT is based on probability and pattern-matching. It learns from bilingual texts and uses models to estimate which translation is most likely correct. It works with phrases, grammar patterns, and statistical rules.
NMT, on the other hand, uses deep learning. It relies on artificial neural networks that learn to understand the meaning behind words and the relationships between them. Instead of translating word by word or phrase by phrase, NMT considers the entire sentence plus the context.
Here’s a side-by-side comparison to make things clearer:
Statistical machine translation (SMT)
Neural machine translation (NMT)
How it works
Statistical models based on bilingual text pairs
Deep learning using neural networks
Translation approach
Phrase-based or syntax-based
End-to-end sentence-level translation
Understanding context
Limited to nearby words or phrases
Understands the entire sentence and context
Training data
Large parallel corpora
Needs large datasets
Resource needs
Less demanding
Needs more memory and processing power
Error types
Issues with word order, too literal
Fluent, but sometimes struggles with accuracy
Fluency
Translations can sound too robotic
Typically natural and fluent translations
Limitations of statistical machine translation
SMT solved big problems in its time. But it also left big gaps, ones that became more obvious as translation got more ambitious.
1. Word order problems
Languages don’t all follow the same sentence structure. What sounds natural in English might be completely wrong in German. SMT often struggled to reorder words correctly, especially in longer or more complex sentences.
2. Lack of true understanding
SMT doesn’t understand meaning. It works by matching patterns. That means it can miss nuance, context, or tone. It might choose a grammatically correct sentence that doesn’t actually say what the original text meant.
3. Data dependency
SMT needs a huge amount of bilingual text to work well. For common language pairs, that’s fine. But for less widely spoken languages (or specialized topics), it’s hard to get enough data to train a reliable model.
4. Mechanical output
Even when it gets the words right, SMT often produces stiff or awkward translations. That’s because it stitches together pieces of phrases rather than thinking about the sentence as a whole.
5. Hard to scale across domains
An SMT model trained on news articles might not perform well on medical texts or legal documents. You’d need separate training data and tuning for each new domain, which takes time and effort.
From numbers to meaning
Statistical machine translation may no longer be the industry standard, but it laid the groundwork for everything that followed. It showed us that machines could learn from data, and that translation didn’t have to be handcrafted rule by rule.
Understanding SMT gives us more than just a history lesson. It helps us see how far we’ve come, and why modern machine translation tools are such a leap forward.
But it also reminds us of something important. Even with massive data and advanced models, translating language isn’t just a technical problem. It’s a deeply human one.
Every advance in machine translation brings us closer to more accurate, more natural, and more inclusive communication across languages. And, go figure, it all started with statistics.
Mia has 13+ years of experience in content & growth marketing in B2B SaaS. During her career, she has carried out brand awareness campaigns, led product launches and industry-specific campaigns, and conducted and documented demand generation experiments. She spent years working in the localization and translation industry.
In 2021 & 2024, Mia was selected as one of the judges for the INMA Global Media Awards thanks to her experience in native advertising. She also works as a mentor on GrowthMentor, a learning platform that gathers the world's top 3% of startup and marketing mentors.
Earning a Master's Degree in Comparative Literature helped Mia understand stories and humans better, think unconventionally, and become a really good, one-of-a-kind marketer. In her free time, she loves studying art, reading, travelling, and writing. She is currently finding her way in the EdTech industry.
Mia’s work has been published on Adweek, Forbes, The Next Web, What's New in Publishing, Publishing Executive, State of Digital Publishing, Instrumentl, Netokracija, Lokalise, Pleo.io, and other websites.
Mia has 13+ years of experience in content & growth marketing in B2B SaaS. During her career, she has carried out brand awareness campaigns, led product launches and industry-specific campaigns, and conducted and documented demand generation experiments. She spent years working in the localization and translation industry.
In 2021 & 2024, Mia was selected as one of the judges for the INMA Global Media Awards thanks to her experience in native advertising. She also works as a mentor on GrowthMentor, a learning platform that gathers the world's top 3% of startup and marketing mentors.
Earning a Master's Degree in Comparative Literature helped Mia understand stories and humans better, think unconventionally, and become a really good, one-of-a-kind marketer. In her free time, she loves studying art, reading, travelling, and writing. She is currently finding her way in the EdTech industry.
Mia’s work has been published on Adweek, Forbes, The Next Web, What's New in Publishing, Publishing Executive, State of Digital Publishing, Instrumentl, Netokracija, Lokalise, Pleo.io, and other websites.
Types of machine translation (and how to choose the right one)
Some types of machine translation systems follow strict grammar rules. Others rely on stats. Today’s most advanced ones use deep learning to mimic how humans speak. Each type has strengths,…
Neural machine translation (NMT) sounds technical and complex. But at its core, it’s just how modern AI translates one language into another. If you’ve ever used Google Translate, watched subtitles…