Brand tone and voice
If you’re translating marketing copy, slogans, or UX content, MT often fails to capture your brand’s personality. You might get the words right, but the feel is off. Luckily, some AI translation tools allow you to “feed” context to them, which improves the output significantly.
Low-resource languages
Languages with fewer available datasets may not perform well in NMT engines. The result? Inconsistent or clunky output.
Sensitive or regulated content
Machine translation can introduce small inaccuracies that can turn into big problems. This is especially true for legal, medical, or financial content where precision is non-negotiable.
Machine translation doesn’t always play nicely with layouts because it lacks visual context. And so, translated text can break UI elements, expand too much, or throw off your visual design.
While some of these limitations are likely to be minimized over time thanks to technological advancements, there is one truth that you need to hear. Here it goes:
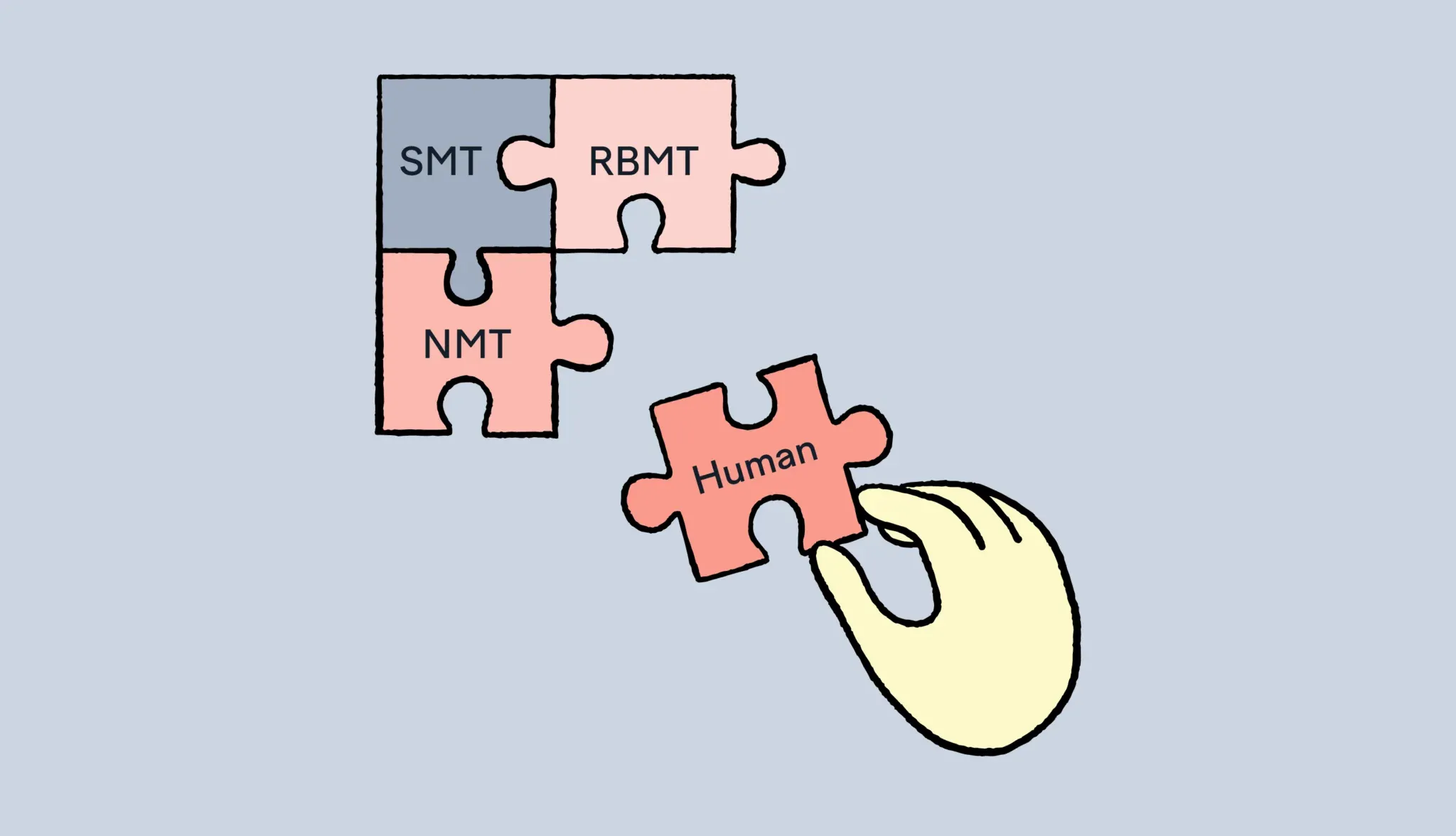
Human input is still relevant (and often critical) in the translation workflow.
How human editing complements machine translation
Post-editing is the step where a human translator reviews and refines machine-generated content.
Sometimes that means fixing a few clunky phrases. Other times, it means rewriting entire sentences to make sure they actually make sense, sound natural, and align with your tone.
Here’s what a human editor brings to the table:
- Fixes small errors that machine translation tools might miss
- Makes the text sound natural and fluent
- Keeps your tone and brand voice on point
- Handles slang, idioms, and cultural nuances
- Ensures consistency across your content
- Brings in domain knowledge when it matters
So, it’s not a question of “either-or”. You should use machine translation tools and help your translators work more efficiently. Let the tech do the heavy lifting, and then the linguists can apply all the fine touches.
Don't just pick a system, pick a strategy
Although it might seem like it, choosing a machine translation system isn’t a technical decision. It’s a strategic one.
Instead of asking “Which machine translation type is best?”, it’s far better to ask the following:
“What does my content need? Why are we translating this in the first place?”
Then look inwards and explore. Is speed more important than tone? Do you need domain accuracy, or just rough understanding? Will a human step in to thoroughly review it, or is the output going to production with minimal quality assurance?
The answers to these questions will guide your setup.
- Use NMT for most modern workflows (it’s fast, fluent, and widely supported)
- Add human editing where tone, accuracy, or context really matter
- Explore hybrid setups or domain-trained engines for specialized use cases
- Think about scale, automation, and how machine translation fits into your larger localization flow
As the last takeaway, remember this. The best translations come as a consequence of building the right systems. This includes tools, people, workflows, and procedures. We know this very well, and that’s why we built Lokalise—to bring all of these elements together.
Want to learn more about machine translation, large language models (LLMs), and AI in translation? Visit Lokalise blog.